Introduction
Welcome to the Gofer documentation! This documentation is a reference for all available features and options of Gofer.
- To kick the tires visit: Getting Started
- To read more about Gofer's Feature set visit: Features
- To understand the why of Gofer visit: Philosophy
Gofer: Run short-lived jobs easily.
{kind=link}
![]()
Gofer is an opinionated, streamlined automation engine designed for the cloud-native era. It's basically remote code execution as a platform.
Gofer focuses on the "what" and "when" of your workloads, leaving the "how" and "where" to pluggable, more sophisticated container orchestrators (such as K8s or Nomad or even local Docker).
It specializes in executing your custom scripts in a containerized environment, making it versatile for both developers and operations teams. Deploy Gofer effortlessly as a single static binary, and manage it using expressive, declarative configurations written in real programming languages.
Its primary function is to execute short-term jobs like code linting, build automation, testing, port scanning, ETL operations, or any task you can containerize and trigger based on events.
Why?:
- This is my idea of fun.
- Modern solutions...
- are too complicated to setup and/or manage.
- lack tight feedback loops while developing pipelines.
- require you to marry your business logic code to pipeline logic code.
- use configuration languages (or sometimes worse...their own DSL) as the interface to express what you want.
- lack extensibility
- It is an experiment to see if theses are all solveable problems in the effort to create a simpler, faster solution.
Features:
- Simple Deployment: Install Gofer effortlessly with a single static binary and manage it through its intuitive command-line interface.
- Language Flexibility: Craft your pipelines in programming languages you're already comfortable with, such as Go or Rust—no more wrestling with unfamiliar YAML.
- Local Testing: Validate and run your pipelines locally, eliminating the guesswork of "commit and see" testing.
- Extensible Architecture: Easily extend Gofer's capabilities by writing your own plugins, backends, and more, in any language via OpenAPI.
- Built-In Storage: Comes with an integrated Object and Secret store for your convenience.
- DAG Support: Harness the power of Directed Acyclic Graphs (DAGs) for complex workflow automation.
- Robust Reliability: Automatic versioning, Blue/Green deployments, and canary releases ensure the stability and dependability of your pipelines.
Demo:

Documentation & Getting Started
If you want to fully dive into Gofer, check out the documentation site!
Install
Extended installation information is available through the documentation site.
Download a specific release:
You can view and download releases by version here.
Download the latest release:
- Linux:
wget https://github.com/clintjedwards/gofer/releases/latest/download/gofer
Build from source:
git clone https://github.com/clintjedwards/gofer && cd gofermake buildls ./target/release/gofer
The Gofer binary comes with a CLI to manage the server as well as act as a client.
Dev Setup
Gofer is setup such that the base run mode is the development mode. So simply running the binary without any additional flags allows easy auth-less development. You can read more about how to deploy Gofer in a production environment here
This is really helpful for users and developers alike since it allows easy access to a runnable server to test pipelines against.
You'll need to install the following first:
To run Gofer dev mode:
Run from the Makefile
Gofer uses flags, env vars, and files to manage configuration (in order of most important). The Makefile already includes all the commands and flags you need to run in dev mode by simply running make run.
In case you want to run without the make file simply run:
cd gofer
export GOFER_WEB_API__LOG_LEVEL=debug
cargo run --bin gofer -- service start
Env aware configuration
To avoid issues when developing Gofer, the development build of Gofer(any binary that was not built with --release)
looks for the CLI config file at .gofer_dev.toml instead of .gofer.toml.
This avoids the headache of having to swap configuration files while actively developing Gofer. But is noted here since it can be confusing if not known.
Editing OpenAPI spec files
Where are the openapi spec files?
Gofer uses OpenAPI to generate a REST API in which is uses both to communicate with extensions and the main web service.
- You can find the OpenAPI spec files located in
sdk/openapi.jsonandgofer/docs/src/assets/openapi.json. - This means you can also access the API reference by going to
/docs/api_reference.htmlin the main web service.
How do we generate new spec files?
Gofer uses oapi-codegen to generate the Golang sdk and progenitor to generate the Rust SDK.
You can download oapi-codegen by performing go install github.com/deepmap/oapi-codegen/v2/cmd/oapi-codegen@latest.
Progenitor is already included as a lib within the generation code.
The OpenAPI Spec files are generated by the web framework used dropshot. It generates the files directly from the API code using Rust proc macros over the direct API function handlers. This creates a sort of chicken and egg problem when attempting to change things and the compile times from using many proc macros are long. This will soon be resolved by using a more trait based approach.
You can run the generate script by using make generate-openapi from the root directory.
Editing Documentation
Documentation is done with mdbook.
To install:
cargo install mdbook
cargo install mdbook-linkcheck
Once you have mdbook you can simply run make run-docs to give you an auto-reloading dev version of the documentation
in a browser.
Regenerating Demo Gif
The Gif on the README page uses vhs; a very handy tool that allows you to write a configuration file which will pop out a gif on the other side.
In order to do this VHS has to run the commands so we must start the server first before we regenerate the gif.
rm -rf /tmp/gofer* # Start with a fresh database
make run # Start the server in dev mode
cd documentation/src/assets
vhs < demo.tape # this will start running commands against the server and output the gif as demo.gif.
Authors
- Clint Edwards - Github
This software is provided as-is. It's a hobby project, done in my free time, and I don't get paid for doing it.
If you're looking for the previous Golang version you can find it here.
How does Gofer work?
Gofer works in a very simple client-server model. You deploy Gofer as a single binary to your favorite VPS and you can configure it to connect to all the tooling you currently use to run containers.
Gofer acts as a scheduling middle man between a user's intent to run a container at the behest of an event and your already established container orchestration system.
Workflow
Interaction with Gofer is mostly done through its command line interface which is included in the same binary as the master service.
General Workflow
- Gofer is connected to a container orchestrator of some sort. This can be just your local docker service or something like K8s or Nomad.
- It launches it's configured extensions (extensions are just containers) and these extensions wait for events to happen or perform some service on behalf of your pipeline.
- Users create pipelines (by configuration file) that define exactly in which order and what containers they would like to run.
- These pipelines don't have to, but usually involve extensions so that pipelines can run automatically.
- Either by extension or manual intervention a pipeline run will start and schedule the containers defined in the configuration file.
- Gofer will collect the logs, exit code, and other essentials from each container run and provide them back to the user along with summaries of how that particular run performed.
Extension Implementation
- When Gofer launches the first thing it does is create the extension containers the same way it schedules any other container.
- The extension containers are all small REST API web services that are implemented using a specific interface provided by the sdk.
- Gofer passes the extension a secret value that only it knows so that the extension doesn't respond to any requests that might come from other sources.
- After the extension is initialized Gofer will subscribe any pipelines that have requested this extension (through their pipeline configuration file) to that extension.
- The extension then takes note of this subscription and waits for the relevant event to happen.
- When the event happens it figures out which pipeline should be alerted and sends an event to the main Gofer process.
- The main gofer process then starts a pipeline run on behalf of the extension.
Glossary
-
Pipeline: A pipeline is a collection of tasks that can be run at once. Pipelines can be defined via a pipeline configuration file. Once you have a pipeline config file you can create a new pipeline via the CLI (recommended) or API.
-
Run: A run is a single execution of a pipeline. A run can be started automatically via extensions or manually via the API or CLI
-
Extension: A extension allow for the extension of pipeline functionality. Extension start-up with Gofer as long running containers and pipelines can subscribe to them to have additional functionality.
-
Task: A task is the lowest unit in Gofer. It is a small abstraction over running a single container. Through tasks you can define what container you want to run, when to run it in relation to other containers, and what variables/secrets those containers should use.
-
Task Execution: A task execution is the programmatic running of a single task container. Referencing a specific task execution is how you can examine the results, logs, and details of one of your tasks on any given run.
FAQ
> I have a job that works with a remote git repository, other CI/CD tools make this trivial, how do I mimic that?
The drawback of this model and architecture is does not specifically cater to GitOps. So certain workflows that come out of the box from other CI/CD tooling will need to be recreated, due to its inherently distributed nature.
Gofer has provided several tooling options to help with this.
There are two problems that need to be solved around the managing of git repositories for a pipeline:
1) How do I authenticate to my source control repository?
Good security practice suggests that you should be managing repository deploy keys, per repository, per team. You can potentially forgo the "per team" suggestion using a "read-only" key and the scope of things using the key isn't too big.
Gofer's suggestion here is to make deploy keys self service and then simply enter them into Gofer's secret store to be used by your pipeline's tasks. Once there you can then use it in each job to pull the required repository.
2) How do I download the repository?
Three strategies:
- Just download it when you need it. Depending on the size of your repository and the frequency of the pull, this can work absolutely fine.
- Use the object store as a cache. Gofer provides an object store to act as a permanent (pipeline-level) or short-lived (run-level) cache for your workloads. Simply store the repository inside the object store and pull down per job as needed.
- Download it as you need it using a local caching git server. Once your repository starts becoming large or you do many
pulls quickly it might make more sense to use a cache1,2. It also makes sense to only download what you
need using git tools like
sparse checkout
https://github.com/google/goblet
https://github.com/jonasmalacofilho/git-cache-http-server
Feature Guide
Write your pipelines in a real programming language.
Other infrastructure tooling tried configuration languages(yaml, hcl).... and they kinda suck1. The Gofer CLI allows you to create your pipelines in a fully featured programming language. Pipelines can be currently be written in Go or Rust2.
DAG(Directed Acyclic Graph) Support.
Gofer provides the ability to run your containers in reference to your other containers.
With DAG support you can run containers:
- In parallel.
- After other containers.
- When particular containers fail.
- When particular containers succeed.
OpenAPI compatible
Gofer uses OpenAPI to construct its API surface. This means that Gofer's API is easy to use, well defined, and can easily be developed for in any language.
The use of OpenAPI gives us two main advantages:
- The most up-to-date API contract can always be found by reading the openapi spec files included in the source.
- Developing against the API for developers working within Golang/Rust simply means importing the provided sdk.
- Developing against the API for developers not working within the Go/Rust language means simply generating an sdk using your language specific tooling
Namespaces
Gofer allows you to separate out your pipelines into different namespaces, allowing you to organize your teams and set permissions based on those namespaces.
Extensions
Extensions are the way users can add extra functionality to their pipelines. For instance the ability to automate their pipelines by waiting on bespoke events (like the passage of time).
Extensions are nothing more than containers themselves that talk to the main process when they require activity.
Gofer out of the box provides some default extensions like cron and interval. But even more powerful than that, it accepts any type of extension you can think up and code using the included extension sdk.
You can view how extensions work by visiting the sample extension 'interval'
Extensions are brought up alongside Gofer as long-running containers that it launches and manages.
Object Store
Gofer provides a built in object store you can access with the Gofer CLI. This object store provides a caching and data transfer mechanism so you can pass values from one container to the next, but also store objects that you might need for all containers.
Secret Store
Gofer provides a built in secret store you can access with the Gofer CLI. This secret store provides a way to pass secret values needed by your pipeline configuration into Gofer.
Events
Gofer provides a list of events for the most common actions performed. You can view this event stream via the Gofer API, allowing you to build on top of Gofer's actions and even using Gofer as a trigger for other events.
External Events
Gofer allows extensions to consume external events. This allows for extensions to respond to webhooks from favorite sites like Github and more.
Pluggable Everything
Gofer plugs into all your favorite backends your team is already using. This means that you never have to maintain things outside of your wheelhouse.
Whether you want to schedule your containers on K8s or AWS Lambda, or maybe you'd like to use an object store that you're more familiar with in minio or AWS S3, Gofer provides either an already created plugin or an interface to write your own.
Initially why configuration languages are used made sense, namely lowering the bar for users who might not know how to program and making it simpler overall to maintain(read: not shoot yourself in the foot with crazy inheritance structures). But, in practice, we've found that they kinda suck. Nobody wants to learn yet another language for this one specific thing. Furthermore, using a separate configuration language doesn't allow you to plug into years of practice/tooling/testing teams have with a certain favorite language.
All pipelines eventually reduce to json, so given the correct libraries your pipelines can be written in any language you like!
Best Practices
In order to schedule workloads on Gofer your code will need to be wrapped in a docker container. This is a short workflow blurb about how to create containers to best work with Gofer.
1) Write your code to be idempotent.
Write your code in whatever language you want, but it's a good idea to make it idempotent. Gofer does not guarantee single container runs (but even if it did that doesn't prevent mistakes from users).
2) Follow 12-factor best practices.
Configuration is the important one. Gofer manages information into containers by environment variables so your code will need to take any input or configuration it needs from environment variables.
3) Keep things simple.
You could, in theory, create a super complicated graph of containers that run off each other. But the main theme of Gofer is simplicity. Make sure you're thinking through the benefits of managing something in separate containers vs just running a monolith container. There are good reasons for both; always err on the side of clarity and ease of understanding.
4) Keep your containers lean.
Because of the potentially distributed nature of Gofer, the larger the containers you run, the greater potential lag time between the start of execution for your container. This is because there is no guarantee that your container will end up on a machine that already has the image. Downloading large images takes a lot of time and a lot of disk space.
Troubleshooting Gofer
This page provides various tips on how to troubleshoot and find issues/errors within Gofer.
Debugging extensions
Extensions are simply long running containers that internally wait for an event to happen and then communicate with Gofer it's API.
There are two main avenues to debug extensions:
gofer extension logs <id>will stream an extension's logs.- Each extension has a
/api/debugendpoint that dumps debug information about that extension.
Debugging Tasks
When tasks aren't working quite right, it helps to have some simple tasks that you can use to debug. Gofer provides a few of these to aid in debugging.
| Name | Image | Description |
|---|---|---|
| envs | ghcr.io/clintjedwards/gofer/debug/envs | Simply prints out all environment variables found |
| fail | ghcr.io/clintjedwards/gofer/debug/fail | Purposely exist with a non-zero exit code. Useful for testing that pipeline failures or alerting works correctly. |
| log | ghcr.io/clintjedwards/gofer/debug/log | Prints a couple paragraphs of log lines with 1 second in-between, useful as a container that takes a while to finish and testing that log following is working correctly |
| wait | ghcr.io/clintjedwards/gofer/debug/wait | Wait a specified amount of time and then successfully exits. |
Gofer's Philosophy
Short version
Gofer focuses on the usage of containers to run workloads that don't belong as long-running applications. At it's core, it is a remote code execution platform. The ability to run containers easily is powerful tool for users who need to run various short-term workloads and don't want to learn a whole new paradigm to do it. Gofer respects the user by inviting them to follow a golden path for how to do things, but also giving them the power to leave it when necessary.
Gofer's core values are:
- Simple as possible, but no simpler.
- Easy to use. Don't get in the way of the user.
- Fast. Computers wait on people not the other way around.
Long version
If you'd like to read more about why Gofer exists and the journey in creating it, you can do so here
API Reference
Getting Started
Let's start by setting up our first Gofer pipeline!
Installing Gofer
Gofer comes as an easy to distribute pre-compiled binary that you can run on your machine locally, but you can always build Gofer from source if need be.
Pre-compiled (Recommended)
You can download the latest version for linux here:
wget https://github.com/clintjedwards/gofer/releases/latest/download/gofer
From Source
cd gofer
cargo build --release
Running the Server Locally
Gofer is deployed as a single static binary allowing you to run the full service locally so you can play with the internals before committing resources to it. Spinning Gofer up locally is also a great way to debug "what would happen if?" questions that might come up during the creation of pipeline config files.
Install Gofer
Install Docker
The way in which Gofer runs containers is called a Scheduler. When deploying Gofer at scale we can deploy it with a more serious container scheduler (Nomad, Kubernetes) but for now we're just going to use the default local docker scheduler included. This simply uses your local instance of docker instance to run containers.
But before we use your local docker service... you have to have one in the first place. If you don't have docker installed, the installation is quick. Rather than covering the specifics here you can instead find a guide on how to install docker for your operating system on its documentation site.
Start the server
By default the Gofer binary is able to run the server in development mode. Simply start the service by:
gofer service start
Create Your First Pipeline Configuration
Before you can start running containers you must tell Gofer what you want to run. To do this we create what is called
a pipeline configuration.
The creation of this pipeline configuration is very easy and can be done in either Golang or Rust. This allows you to use a fully-featured programming language to organize your pipelines, instead of dealing with YAML mess.
Let's Go!
As an example, let's just copy a pipeline that has been given to us already. We'll use Go as our language, which means you'll need to install it if you don't have it. The Gofer repository gives us a simple pipeline that we can copy and use.
Let's first create a folder where we'll put our pipeline:
mkdir /tmp/simple_pipeline
Then let's copy the Gofer provided pipeline's main file into the correct place:
cd /tmp/simple_pipeline
wget https://raw.githubusercontent.com/clintjedwards/gofer/main/examplePipelines/go/simple/main.go
This should create a main.go file inside our /tmp/simple_pipeline directory.
Lastly, let's initialize the new Golang program:
To complete our Go program we simply have to initialize it with the go mod command.
go mod init test/simple_pipeline
go mod tidy
The pipeline we generated above gives you a very simple pipeline with a few pre-prepared testing containers. You should be able to view it using your favorite IDE.
The configuration itself is very simple. Essentially a pipeline contains of a few parts:
> Some basic attributes so we know what to call it and how to document it.
err := sdk.NewPipeline("simple", "Simple Pipeline").
Description("This pipeline shows off a very simple Gofer pipeline that simply pulls in " +
...
> The containers we want to run are defined through tasks.
...
sdk.NewTask("simple_task", "ubuntu:latest").
Description("This task simply prints our hello-world message and exits!").
Command("echo", "Hello from Gofer!").Variable("test", "sample"),
...
Register your pipeline
Now we will register your newly created pipeline configuration with Gofer!
More CLI to the rescue
From your terminal, lets use the Gofer binary to run the following command, pointing Gofer at your newly created pipeline folder:
gofer up ./tmp/simple_pipeline
Examine created pipeline
It's that easy!
The Gofer command line application uses your local Golang compiler to compile, parse, and upload your pipeline configuration to Gofer.
You should have received a success message and some suggested commands:
✓ Created pipeline: [simple] "Simple Pipeline"
View details of your new pipeline: gofer pipeline get simple
Start a new run: gofer run start simple
We can view the details of our new pipeline by running:
gofer pipeline get simple
If you ever forget your pipeline ID you can list all pipelines that you own by using:
gofer pipeline list
Start a Run
Now that we've set up Gofer, defined our pipeline, and registered it we're ready to actually run our containers.
Press start
gofer pipeline run simple
What happens now?
When you start a run Gofer will attempt to schedule all your tasks according to their dependencies onto your chosen scheduler. In this case that scheduler is your local instance of Docker.
Your run should be chugging along now!
View a list of runs for your pipeline:
gofer run list simple
View details about your run:
gofer run get simple 1
List the containers that executed during the run:
gofer task list simple 1
View a particular container's details during the run:
gofer task get simple 1 <task_id>
Stream a particular container's logs during the run:
gofer task logs simple 1 <task_id>
What's Next?
Anything!
- Keep playing with Gofer locally and check out all the CLI commands.
- Spruce up your pipeline definition!
- Learn more about Gofer terminology.
- Deploy Gofer for real. Pair it with your favorite scheduler and start using it to automate your jobs.
Pipeline Configuration
A pipeline is a directed acyclic graph of tasks that run together. A single execution of a pipeline is called a run. Gofer allows users to configure their pipeline via a configuration file written in Golang or Rust.
The general hierarchy for a pipeline is:
namespace
\_ pipeline
\_ run
\_ task
That is to say:
- A namespace might contain multiple pipelines.
- A pipeline is made up of tasks/containers to be run.
- Every time a pipeline is executed it is done through the concept of a run which makes sure the containers are executed properly.
SDK
Creating a pipeline involves using the SDK currently written in Go or Rust.
Small Walkthrough
To introduce some of the concepts slowly, lets build a pipeline step by step. We'll be using Go as our pipeline
configuration language and this documentation assumes you've already set up a new Go project and are operating
in a main.go file. If you haven't you can set up one
following the guide instructions.
A Simple Pipeline
Every pipeline is initialized with a simple pipeline declaration. It's here that we will name our pipeline, giving it a machine referable ID and a human referable name.
err := sdk.NewPipeline("simple", "My Simple Pipeline")
It's important to note here that while your human readable name ("My Simple Pipeline" in this case) can contain a large array of characters the ID can only container alphanumeric letters, numbers, and hyphens. Any other characters will result in an error when attempting to register the pipeline, due to each id needing to be URL safe.
Add a Description
Next we'll add a simple description to remind us what this pipeline is used for.
err := sdk.NewPipeline("simple", "My Simple Pipeline").
Description("This pipeline is purely for testing purposes.")
The SDK uses a builder pattern, which allows us to simply add another function onto our Pipeline object which we can type our description into.
Add a task
Lastly let's add a task(container) to our pipeline. We'll add a simple ubuntu container and change the command that gets run on container start to just say "Hello from Gofer!".
err := sdk.NewPipeline("simple", "My Simple Pipeline").
Description("This pipeline is purely for testing purposes.").
Tasks(sdk.NewTask("simple-task", "ubuntu:latest").
Description("This task simply prints our hello-world message and exists!").
Command("echo", "Hello from Gofer!"),
)
We used the Tasks function to add multiple tasks and then we use the SDK's NewTask function to create a task.
You can see we:
- Give the task an ID, much like our pipeline earlier.
- Specify which image we want to use.
- Tack on a description.
- And then finally specify the command.
To tie a bow on it, we add the .Finish() function to specify that our pipeline is in it's final form.
err := sdk.NewPipeline("my-pipeline", "My Simple Pipeline").
Description("This pipeline is purely for testing purposes.").
Tasks(sdk.NewTask("simple-task", "ubuntu:latest").
Description("This task simply prints our hello-world message and exists!").
Command("echo", "Hello from Gofer!"),
).Finish()
That's it! This is a fully functioning pipeline.
You can run and test this pipeline much like you would any other code you write. Running it will produce a JSON output which Gofer uses to pass to the server.
You can find examples like this and more in example pipelines
Extra Examples
Auto Inject API Tokens
Gofer has the ability to auto-create and inject a token into your tasks. This is helpful if you want to use the Gofer CLI or the Gofer API to communicate with Gofer at some point in your task.
You can tell Gofer to do this by using the InjectAPIToken function for a particular task.
The token will be cleaned up the same time the logs for a particular run is cleaned up.
err := sdk.NewPipeline("my-pipeline", "My Simple Pipeline").
Description("This pipeline is purely for testing purposes.").
Tasks(
sdk.NewTask("simple-task", "ubuntu:latest").
Description("This task simply prints our hello-world message and exists!").
Command("echo", "Hello from Gofer!").InjectAPIToken(true),
).Finish()
Tasks
Gofer's abstraction for running a container is called a Task. Specifically Tasks are containers you point Gofer to and configure to perform some workload.
A Task can be any container you want to run. In the
Getting Started example we take a regular standard
ubuntu:latest container and customize it to run a passed in bash script.
Tasks(
sdk.NewTask("simple_task", "ubuntu:latest").
Description("This task simply prints our hello-world message and exists!").
Command("echo", "Hello from Gofer!"),
)
Task Environment Variables and Configuration
Gofer handles container configuration the cloud native way. That is to say every configuration is passed in as an environment variable. This allows for many advantages, the greatest of which is standardization.
As a user, you pass your configuration in via the Variable(s) flavor of functions in your pipeline config.
When a container is run by Gofer, the Gofer scheduler has the potential to pass in configuration from multiple sources1:
- Your pipeline configuration: Configs you pass in by using the
Variable(s)functions. - Runtime Configurations: When a pipeline is run you can pass in variables that the pipeline should be run with. This is also how extensions pass in variable configurations.
- Gofer's system configurations: Gofer will pass in system configurations that might be helpful to the user. (For example, what current pipeline is running.)[^2]
The exact key names injected for each of these configurations can be seen on any task by getting that task's details:
gofer task get <pipeline_name> <run_id> <task_id>
These sources are ordered from most to least important. Since the configuration is passed in a "Key => Value"
format any conflicts between sources will default to the source with the greater importance. For instance,
a pipeline config with the key GOFER_PIPELINE_ID will replace the key of the same name later injected by the
Gofer system itself.
| Key | Description |
|---|---|
GOFER_PIPELINE_ID | The pipeline identification string. |
GOFER_RUN_ID | The run identification number. |
GOFER_TASK_ID | The task execution identification string. |
GOFER_TASK_IMAGE | The image name the task is currently running with. |
GOFER_API_TOKEN | Optional. Runs can be assigned a unique Gofer API token automatically. This makes it easy and manageable for tasks to query Gofer's API and do lots of other convenience tasks. |
What happens when a task is run?
The high level flow is:
- Gofer checks to make sure your task configuration is valid.
- Gofer parses the task configuration's variables list. It attempts replace any substitution variables with their actual values from the object or secret store.
- Gofer then passes the details of your task to the configured scheduler, variables are passed in as environment variables.
- Usually this means the scheduler will take the configuration and attempt to pull the
imagementioned in the configuration. - Once the image is successfully pulled the container is then run with the settings passed.
Server Configuration
Gofer runs as a single static binary that you deploy onto your favorite VPS.
While Gofer will happily run in development mode without any additional configuration, this mode is NOT recommended for production workloads and not intended to be secure.
Instead Gofer allows you to edit it's startup configuration allowing you to configure it to run on your favorite container orchestrator, object store, and/or secret backend.
Setup
There are a few steps to setting up the Gofer service for production:
1) Configuration
First you will need to properly configure the Gofer service.
Gofer accepts configuration through environment variables or a configuration file. If a configuration key is set both in an environment variable and in a configuration file, the value of the environment variable's value will be the final value.
You can view a list of environment variables Gofer takes by using the gofer service start -h command. It's
important to note that each environment variable starts with a prefix of GOFER_WEB_. So setting the api.log_level
configuration can be set as:
export GOFER_WEB_API__LOG_LEVEL=debug
Configuration file
The Gofer service configuration file is written in TOML.
Load order
The Gofer service looks for its configuration in one of several places (ordered by first searched):
- /etc/gofer/gofer_web.toml
Bare minimum production file
These are the bare minimum values you should populate for a production ready Gofer configuration.
The values below should be changed depending on your environment; leaving them as they currently are will lead to loss of data on server restarts.
2) Running the binary
You can find the most recent releases of Gofer on the github releases page..
Simply use whatever configuration management system you're most familiar with to place the binary on your chosen
VPS and manage it. You can find a quick and dirty wget command to pull the
latest version in the getting started documentation.
3) First steps
You will notice upon service start that the Gofer CLI is unable to make any requests due to permissions.
You will first need to handle the problem of auth. Every request to Gofer must use an API key so Gofer can appropriately direct requests.
More information about auth in general terms can be found here.
To create your root/bootstrap token use the command: gofer token bootstrap
The token returned is a bootstrap token and as such has access to all routes within Gofer. It is advised that:
- You use this token only in admin situations and to generate other lesser permissioned tokens.
- Store this token somewhere safe.
From here you can use your root token to provision extra, lower permissioned tokens for everyday use.
When communicating with Gofer through the CLI you can set the token to be automatically passed per request in one of many ways.
Configuration Reference
This page might be outdated.
Gofer has a variety of parameters that can be specified via environment variables or the configuration file.
To view a list of all possible environment variables simply type: gofer service start -h.
The most up to date config file values can be found by reading the code or running the command above, but a best effort key and description list is given below.
If examples of these values are needed you can find a sample file by using gofer service init-config.
Values
API
| name | type | default | description |
|---|---|---|---|
| event_log_retention | string (duration) | 4380h | Controls how long Gofer will hold onto events before discarding them. This is important factor in disk space and memory footprint. Example: Rough math on a 5,000 pipeline Gofer instance with a full 6 months of retention puts the memory and storage footprint at about 9GB. |
| event_prune_interval | string | 3h | How often to check for old events and remove them from the database. Will only remove events older than the value in event_log_retention. |
| ignore_pipeline_run_events | boolean | false | Controls the ability for the Gofer service to execute jobs on startup. If this is set to false you can set it to true manually using the CLI command gofer service toggle-event-ingress. |
| log_level | string | debug | The logging level that is output. It is common to start with info. |
| run_parallelism_limit | int | N/A | The limit automatically imposed if the pipeline does not define a limit. 0 is unlimited. |
| task_execution_logs_dir | string | /tmp | The path of the directory to store task execution logs. Task execution logs are stored as a text file on the server. |
| task_execution_log_expiry | int | 20 | The total amount of runs before logs of the oldest run will be deleted. |
| task_execution_stop_timeout | string | 5m | The amount of time Gofer will wait for a container to gracefully stop before sending it a SIGKILL. |
| external_events_api | block | N/A | The external events API controls webhook type interactions with extensions. HTTP requests go through the events endpoint and Gofer routes them to the proper extension for handling. |
| object_store | block | N/A | The settings for the Gofer object store. The object store assists Gofer with storing values between tasks since Gofer is by nature distributed. This helps jobs avoid having to download the same objects over and over or simply just allows tasks to share certain values. |
| secret_store | block | N/A | The settings for the Gofer secret store. The secret store allows users to securely populate their pipeline configuration with secrets that are used by their tasks, extension configuration, or scheduler. |
| scheduler | block | N/A | The settings for the container orchestrator that Gofer will use to schedule workloads. |
| server | block | N/A | Controls the settings for the Gofer API service properties. |
| extensions | block | N/A | Controls settings for Gofer's extension system. Extensions are different workflows for running pipelines usually based on some other event (like the passing of time). |
Example
[api]
ignore_pipeline_run_events = false
run_parallelism_limit = 200
pipeline_version_retention = 10
event_log_retention = 15768000 # 6 months
event_prune_interval = 604800 # 1 week
log_level = "info"
task_execution_log_retention = 50 # total runs
task_execution_logs_dir = "/tmp"
task_execution_stop_timeout = 300 # 5 mins
admin_key = "test"
Development (block)
Special feature flags to make development easier
| name | type | default | description |
|---|---|---|---|
| bypass_auth | boolean | false | Skip authentication for all routes. |
| default_encryption | boolean | false | Use default encryption key to avoid prompting for a unique one. |
| pretty_logging | boolean | false | Turn on human readable logging instead of JSON. |
| use_localhost_tls | boolean | false | Use embedded localhost certs instead of prompting the user to provide one. |
Example
[development]
pretty_logging = true # Tells the logging package to use human readable output.
bypass_auth = true # Turns off auth.
use_included_certs = true # Automatically loads localhost certs for development.
External Events API (block)
The external events API controls webhook type interactions with extensions. HTTP requests go through the events endpoint and Gofer routes them to the proper extension for handling.
| name | type | default | description |
|---|---|---|---|
| enable | boolean | true | Enable the events api. If this is turned off the events http service will not be started. |
| host | string | localhost:8081 | The address and port to bind the events service to. |
Example
[external_events]
enable = true
bind_address = "0.0.0.0:8081"
use_tls = false
Object Store (block)
The settings for the Gofer object store. The object store assists Gofer with storing values between tasks since Gofer is by nature distributed. This helps jobs avoid having to download the same objects over and over or simply just allows tasks to share certain values.
You can find more information on the object store block here.
| name | type | default | description |
|---|---|---|---|
| engine | string | sqlite | The engine Gofer will use to store state. The accepted values here are "sqlite". |
| pipeline_object_limit | int | 50 | The limit to the amount of objects that can be stored at the pipeline level. Objects stored at the pipeline level are kept permanently, but once the object limit is reach the oldest object will be deleted. |
| run_object_expiry | int | 50 | Objects stored at the run level are unlimited in number, but only last for a certain number of runs. The number below controls how many runs until the run objects for the oldest run will be deleted. Ex. an object stored on run number #5 with an expiry of 2 will be deleted on run #7 regardless of run health. |
Sqlite (block)
The sqlite store is a built-in, easy to use object store. It is meant for development and small deployments.
| name | type | default | description |
|---|---|---|---|
| path | string | /tmp/gofer-object.db | The path of the file that sqlite will use. If this file does not exist Gofer will create it. |
| sqlite | block | N/A | The sqlite storage engine. |
[object_store]
engine = "sqlite"
pipeline_object_limit = 50
run_object_expiry = 50
[object_store.sqlite]
path = "/tmp/gofer_objects.db"
Secret Store (block)
The settings for the Gofer secret store. The secret store allows users to securely populate their pipeline configuration with secrets that are used by their tasks, extension configuration, or scheduler.
You can find more information on the secret store block here.
| name | type | default | description |
|---|---|---|---|
| engine | string | sqlite | The engine Gofer will use to store state. The accepted values here are "sqlite". |
| sqlite | block | N/A | The sqlite storage engine. |
Sqlite (block)
The sqlite store is a built-in, easy to use object store. It is meant for development and small deployments.
| name | type | default | description |
|---|---|---|---|
| path | string | /tmp/gofer-secret.db | The path of the file that sqlite will use. If this file does not exist Gofer will create it. |
| encryption_key | string | "changemechangemechangemechangeme" | Key used to encrypt keys to keep them safe. This encryption key is responsible for facilitating that. It MUST be 32 characters long and cannot be changed for any reason once it is set or else all data will be lost. |
[secret_store]
engine = "sqlite"
[secret_store.sqlite]
path = "/tmp/gofer_secrets.db"
encryption_key = "changemechangemechangemechangeme"
Scheduler (block)
The settings for the container orchestrator that Gofer will use to schedule workloads.
You can find more information on the scheduler block here.
| name | type | default | description |
|---|---|---|---|
| engine | string | sqlite | The engine Gofer will use as a container orchestrator. The accepted values here are "docker". |
| docker | block | N/A | Docker is the default container orchestrator and leverages the machine's local docker engine to schedule containers. |
Docker (block)
Docker is the default container orchestrator and leverages the machine's local docker engine to schedule containers.
| name | type | default | description |
|---|---|---|---|
| prune | boolean | false | Controls if the docker scheduler should periodically clean up old containers. |
| prune_interval | string | 24h | Controls how often the prune container job should run. |
[scheduler]
engine = "docker"
[scheduler.docker]
prune = true
prune_interval = 604800
timeout = 300 # Should be the same or more than the task_execution_stop_timeout
Server (block)
Controls the settings for the Gofer service's server properties.
| name | type | default | description |
|---|---|---|---|
| host | string | localhost:8080 | The address and port for the service to bind to. |
| shutdown_timeout | string | 15s | The time Gofer will wait for all connections to drain before exiting. |
| tls_cert_path | string | The TLS certificate Gofer will use for the main service endpoint. This is required. | |
| tls_key_path | string | The TLS certificate key Gofer will use for the main service endpoint. This is required. | |
| storage_path | string | /tmp/gofer.db | Where to put Gofer's sqlite database. |
| storage_results_limit | int | 200 | The amount of results Gofer's database is allowed to return on one query. |
[server]
url = "http://localhost:8080"
bind_address = "0.0.0.0:8080"
extension_address = "172.17.0.1:8080"
shutdown_timeout = 15
storage_path = "/tmp/gofer.db"
storage_results_limit = 200
use_tls = false
Extensions (block)
Controls settings for Gofer's extension system. Extensions are different workflows for running pipelines usually based on some other event (like the passing of time).
You can find more information on the extension block here.
| name | type | default | description |
|---|---|---|---|
| install_base_extensions | boolean | true | Attempts to automatically install the cron and interval extensions on first startup. |
| stop_timeout | string | 5m | The amount of time Gofer will wait until extension containers have stopped before sending a SIGKILL. |
| tls_cert_path | string | The TLS certificate path Gofer will use for the extensions. This should be a certificate that the main Gofer service will be able to access. | |
| tls_key_path | string | The TLS certificate path key Gofer will use for the extensions. This should be a certificate that the main Gofer service will be able to access. |
[extensions]
install_std_extensions = true
stop_timeout = 300 # 5 mins
use_tls = false
Authentication and Authorization
Gofer's authentication and authorization systems are designed to be lightweight and unobtrusive, allowing you to focus on your tasks with minimal interference. The permissioning system is based on Role-Based Access Control (RBAC) and is primarily used to prevent certain token holders, such as extensions, from accessing excessive parts of the system.
For most users, this means the ability to categorize users into distinct groups, typically at the namespace or pipeline level.
Authorization in Gofer is token-based, a principle that extends seamlessly to the frontend as well.
Authorization
Gofer organizes permissions into roles, which are then assigned to specific tokens. These tokens grant access based on the permissions associated with their roles.
Roles
Roles are collections of permissions. The most significant role is the bootstrap role, which is a special role. The bootstrap role is equivalent to a root role and is assigned to the first token you receive within Gofer.
Gofer also includes 'system roles' which are special roles that cannot be modified or removed. These roles are generally used by other components of Gofer for specific purposes or are there for your convenience.
You can view a list of these roles by using the gofer role list command and identifying the roles
where system_role is marked as true.
Permissions
Permissions in Gofer are composed of two key components: "Resources" and "Actions."
Resources
Resources refer to specific groups of objects or collections within Gofer. Below is an example list of Gofer resources:
#![allow(unused)] fn main() { pub enum Resource { Configs, Deployments, Events, Extensions(String), Namespaces(String), Objects, Permissions, Pipelines(String), Runs, Secrets, Subscriptions, System, TaskExecutions, Tokens, } }
Some resources may include what Gofer refers to as "targets." Targets allow the creator of the permission to specify particular resources or a set of resources. The true power of targets lies in their ability to leverage regular expressions (regex).
For example, you might want to grant access to all namespaces that begin with a specific prefix.
To achieve this, you would create a role similar to the following:
# Create a new role with permissions limited to the devops namespaces.
POST https://gofer.clintjedwards.com/api/roles
gofer-api-version: v0
Content-Type: application/json
Authorization: Bearer {{secret}}
{
"id": "devops",
"description": "Access only to namespaces that start with devops",
"permissions": [
{
"actions": [
"read",
"write",
"delete"
],
"resources": [
{ "resource": "namespaces", "target": "^devops.*" },
{ "resource": "pipelines", "target": ".*" }
]
}
]
}
HTTP 201
This grants full read, write, and delete permissions for any namespace that begins with "devops"
Actions
Actions are straightforward. Each route in Gofer is associated with an action, which typically corresponds to the HTTP method used (e.g., GET, POST, DELETE). Only tokens with the correct combination of resource and action are permitted to proceed.
Authentication
Before you can start using Gofer, you need to obtain an API token. You can retrieve the
bootstrap token using the gofer token bootstrap command or by making a request to the /api/tokens/bootstrap route.
Once a bootstrap token is collected it can no longer be collected.
How to auth via the API
Gofer requires two headers for successful authentication:
Authorization: Bearer <token>gofer-api-version: v<version_number>
How to auth via the CLI
The Gofer CLI accepts multiple methods for setting a token once you have one.
External Events
Gofer has an alternate endpoint specifically for external events streams1. This endpoint takes in http requests from the outside and passes them to the relevant extension.
You can find more about external event configuration in the configuration-values reference.
enable = true
bind_address = "0.0.0.0:8081"
use_tls = false
It works like this:
-
When the Gofer service is started it starts the external events service on a separate port per the service configuration settings. It is also possible to just turn off this feature via the same configuration file.
-
External services can send Gofer http requests with payloads and headers specific to the extension they're trying to communicate with. It's possible to target specific extensions by using the
/eventsendpoint.ex: https://mygofer.mydomain.com/events/github <- #extension label -
Gofer serializes and forwards the request to the relevant extension where it is validated for authenticity of sender and then processed.
-
A extension may then handle this external event in any way it pleases. For example, the Github extension takes in external events which are expected to be Github webhooks and starts a pipeline if the event type matches one the user wanted.
The reason for the alternate endpoint is due to the security concerns with sharing the same endpoint as the main API service of the Gofer API. Since this endpoint is different you can now specifically set up security groups such that it is only exposed to IP addresses that you trust without exposing those same address to Gofer as a whole.
Scheduler
Gofer runs the containers you reference in the pipeline configuration via a container orchestrator referred to here as a "scheduler".
The vision of Gofer is for you to use whatever scheduler your team is most familiar with.
Supported Schedulers
The only currently supported scheduler is local docker. This scheduler is used for small deployments and development work.
How to add new Schedulers?
Schedulers are pluggable, but for them to maintain good performance and simplicity the code that orchestrates them must be added to the schedulers folder within Gofer(which means they have to be written in Rust).
Docker scheduler
The docker scheduler uses the machine's local docker engine to run containers. This is great for small or development workloads and very simple to implement. Simply download docker and go!
[scheduler]
engine = "docker"
[scheduler.docker]
prune = true
prune_interval = 604800
timeout = 300
Configuration
Docker needs to be installed and the Gofer process needs to have the required permissions to run containers upon it.
Other than that the docker scheduler just needs to know how to clean up after itself.
| Parameter | Type | Default | Description |
|---|---|---|---|
| prune | bool | true | Whether or not to periodically clean up containers that are no longer in use. If prune is not turned on eventually the disk of the host machine will fill up with different containers that have run over time. |
| prune_interval | int | 604800 | How often to run the prune job. Depending on how many containers you run per day this value could easily be set to monthly. |
| timeout | int | 300 | The timeout for the request to the docker service. Should be the same or more than the task_execution_stop_timeout |
Object Store
Gofer provides an object store as a way to share values and objects between containers. It can also be used as a cache. It is common for one container to run, generate an artifact or values, and then store that object in the object store for the next container or next run. The object store can be accessed through the Gofer CLI or through the normal Gofer API.
Gofer divides the objects stored into two different lifetime groups:
Pipeline-level objects
Gofer can store objects permanently for each pipeline. You can store objects at the pipeline-level by using the gofer pipeline object store command:
gofer pipeline object put my-pipeline my_key1=my_value5
gofer pipeline object get my-pipeline my_key1
The limitation to pipeline level objects is that they have a limit of the number of objects that can be stored per-pipeline. Once that limit is reached the oldest object in the store will be removed for the newest object.
Run-level objects
Gofer can also store objects on a per-run basis. Unlike the pipeline-level objects run-level do not have a limit to how many can be stored, but instead have a limit of how long they last. Typically after a certain number of runs a object stored at the run level will expire and that object will be deleted.
You can access the run-level store using the run level store CLI commands. Here is an example:
gofer run object put simple_pipeline my_key=my_value
gofer run object get simple_pipeline my_key
Supported Object Stores
The only currently supported object store is the sqlite object store. Reference the configuration reference for a full list of configuration settings and options.
How to add new Object Stores?
Object stores are pluggable, but for them to maintain good performance and simplicity the code that orchestrates them must be added to the object_store folder within Gofer(which means they have to be written in Rust).
Sqlite object store
The sqlite object store is great for development and small deployments.
[object_store]
engine = "sqlite"
pipeline_object_limit = 50
run_object_expiry = 50
[object_store.sqlite]
path = "/tmp/gofer_objects.db"
Configuration
Sqlite needs to create a file on the local machine making the only parameter it accepts a path to the database file.
| Parameter | Type | Default | Description |
|---|---|---|---|
| path | string | /tmp/gofer-object.db | The path on disk to the sqlite db file |
Secret Store
Gofer provides a secret store as a way to enable users to pass secrets into pipeline configuration files.
The secrets included in the pipeline file use a special syntax so that Gofer understands when it is given a secret value instead of a normal variable.
[secret_store]
engine = "sqlite"
Supported Secret Stores
The only currently supported secret store is the sqlite object store. Reference the configuration reference for a full list of configuration settings and options.
How to add new Secret Stores?
Secret stores are pluggable, but for them to maintain good performance and simplicity the code that orchestrates them must be added to the secret_store folder within Gofer(which means they have to be written in Rust).
Sqlite secret store
The sqlite object store is great for development and small deployments.
[secret_store]
engine = "sqlite"
[secret_store.sqlite]
path = "/tmp/gofer_secrets.db"
encryption_key = "changemechangemechangemechangeme"
Configuration
Sqlite needs to create a file on the local machine making the only parameter it accepts a path to the database file.
| Parameter | Type | Default | Description |
|---|---|---|---|
| path | string | /tmp/gofer-secret.db | The path on disk to the sqlite b file |
| encryption_key | string | 32 character key required to encrypt secrets |
Extensions
Extensions are Gofer's way of adding additional functionality to pipelines. You can subscribe your pipeline to an extension, allowing that extension to give your pipeline extra powers.
The most straight-forward example of this, is the interval extension. This extension allows your pipeline to run everytime some amount of time has passed. Let's say you have a pipeline that needs to run every 5 mins. You would subscribe your pipeline to the interval extension using the gofer cli command gofer extension sub internal every_5_seconds set to an interval of 5m.
On startup, Gofer launches the interval extension as a long-running container. When your pipeline subscribes to it. The interval extension starts a timer and when 5 minutes have passed the extension sends an API request to Gofer, causing Gofer to run your pipeline.
Gofer Provided Extensions
You can create your own extensions, but Gofer provides some provided extensions for use.
How do I install a Extension?
Extensions must first be installed by Gofer administrators before they can be used. They can be installed by the CLI. For more information on how to install a specific extension run:
gofer extension install -h
How do I configure a Extension?
Extensions allow for both system and pipeline configuration1. Meaning they have both Global settings that apply to all pipelines and Pipeline specific settings. This is what makes them so dynamically useful!
Pipeline Configuration
Most Extensions allow for some pipeline specific configuration usually referred to as "Parameters" or "Pipeline configuration".
These variables are passed when the user subscribes their pipeline to the extension. Each extension defines what this might be in it's documentation.
System Configuration
Most extensions have system configurations which allow the administrator or system to inject some needed variables. These are defined when the Extension is installed.
See a specific Extension's documentation for the exact variables accepted and where they belong.
How to add new Extensions/ How do I create my own?
Just like tasks, extensions are simply containers! Making them easily testable and portable. To create a new extension you simply use the included Gofer SDK.
The SDK provides an interface in which a well functioning GRPC service will be created from your concrete implementation.
//TODO()
Provided Extensions
Gofer provides some pre-written extensions for quick use:
| name | image | included by default | description |
|---|---|---|---|
| interval | ghcr.io/clintjedwards/gofer/extensions/interval:latest | yes | Interval triggers a run after a predetermined amount of time has passed. |
| cron | ghcr.io/clintjedwards/gofer/extensions/cron:latest | yes | Cron is used for longer termed, more nuanced intervals. For instance, running a pipeline every year on Christmas. |
| github | ghcr.io/clintjedwards/gofer/extensions/github:latest | no | Allow your pipelines to run based on branch, tag, or release activity. |
Cron Extension
Cron allows users to schedule pipeline runs on long term intervals and specific days.
It uses a stripped down version of the cron syntax to do so:
Field Allowed values Allowed special characters
Minutes 0-59 * , -
Hours 0-23 * , -
Day of month 1-31 * , -
Month 1-12 * , -
Day of week 0-6 * , -
Year 1970-2100 * , -
┌───────────── minute (0 - 59)
│ ┌───────────── hour (0 - 23)
│ │ ┌───────────── day of the month (1 - 31)
│ │ │ ┌───────────── month (1 - 12)
│ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday)
│ │ │ │ │ ┌───────────── Year (1970-2100)
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
* * * * * *
Pipeline Configuration
expression<string>: Specifies the cron expression of the interval desired.
Every year on Xmas
gofer pipeline subscribe simple cron yearly_on_xmas -s expression="0 1 25 12 * *"
Extension Configuration
None
Interval Extension
Interval simply runs the subscribed pipeline at the given time interval continously.
Parameters/Pipeline Configuration
every<string>: Specifies the time duration between events. Unless changed via the extension configuration, the minimum for this is 5 mins.
gofer pipeline subscribe simple interval every_five_mins -s every="5m"
Extension Configuration
Extension configurations are set upon extension startup and cannot be changed afterwards without restarting said extension.
| EnvVar | Default | Description |
|---|---|---|
| MIN_DURATION | "5m" | The minimum duration users can set their pipelines to run |
Github Extension
The Github extension allows Gofer pipelines to be run on Github webhook events. This makes it possible to write event driven workloads that depend on an action happening on Github.
See the events section below for all supported events and the environment variables they pass to each pipeline.
Due to the nature of Github's API and webhooks, you'll need to first set up a new Github app to use with Gofer's Github extension.
Steps to accomplish this can be found in the additional steps section.
The Github extension requires the external events feature of Gofer in order to accept webhooks from Github's servers. This requires your application to take traffic from external, potentially unknown sources.
Visit the external events page for more information on how to configure Gofer's external events endpoint.
If Github is your only external extension, to increase security consider limiting the IP addresses that can access Gofer's external events endpoint.
Pipeline Configuration
| Key | Default | Description |
|---|---|---|
| repository | Required | The Github repository you would like to listen for events from. The format is in the form. |
| event_filter | Required | The event/action combination the pipeline will be triggered upon. It is presented in the form: <event>/<action1>,<action2>.... For events that do not have actions or if you simply want to trigger on any action, just putting the <event> will suffice. |
If you don't include actions on an event that has multiple, Gofer will be triggered on any action. You can find a list of events and their actions here(Actions listed as 'activity type' in Github nomenclature.): https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows
Example
gofer pipeline subscribe simple github run_tests \
-s "repository=clintjedwards/experimental" \
-s "event_filter=pull_request_with_check/opened,synchronize,reopened"
Extension Configuration
Extension configurations are set upon startup and cannot be changed afterwards.
The Github extension requires the setup and use of a new Github app. You can view setup instructions below which will walk you through how to retrieve the required env var variables.
| Key | Default | Description |
|---|---|---|
| APP_ID | Required | The Github app ID |
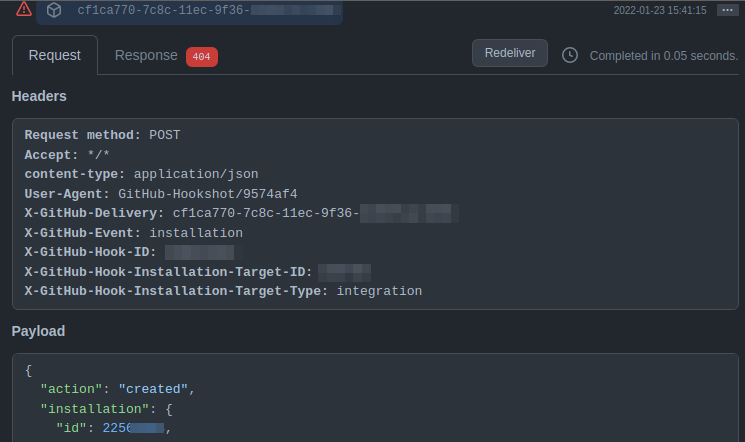
| APP_INSTALLATION | Required | The Github installation ID. This can be found by viewing the webhook payload delivery. See a more details walkthrough on where to find this below. |
| APP_KEY | Required | The base64'd private key of the Github app. This can be generated during Github app creation time. |
| APP_WEBHOOK_SECRET | Required | The Github app webhook secret key. This should be a long, randomized character string. It will be used to verify that an event came from Github and not another source. |
Example
gofer extension install github ghcr.io/clintjedwards/gofer/extension_github:latest \
-c "APP_ID=112348" \
-c "APP_INSTALLATION=99560091" \
-c "APP_KEY=TUtkUnhYY01LTUI1ejgzZU84MFhKQWhoNnBka..." \
-c "APP_WEBHOOK_SECRET=somereallylongstringofcharacters"
Additional setup
Due to the nature of Github's API and webhooks, you'll need to first set up a new Github app to use with Gofer's Github extension. Once this app has been set up, you'll have access to all the required environment variables that you'll need to pass into Gofer's server configuration.
Here is a quick and dirty walkthrough on the important parts of setting up the Github application.
1. Create a new Github application:
Github's documentation will be the most up to date and relevant so please see their walkthrough.
On the configuration page for the new Github application the following should be noted:
-
APP ID: Take note of the id; it will be used later for extension configuration.
-
Webhook URL: Should be the address of your Gofer's external extension instance and pointing to the events/github endpoint:
ex: https://mygoferinstance.yourdomain.com/external/github -
Webhook Secret: Make this a secure, long, random string of characters and note it for future extension configuration.
-
Private Keys: Generate a private key and store it somewhere safe. You'll need to base64 this key and insert it into the extension configuration.
base64 ~/Desktop/myorg-gofer.2022-01-24.private-key.pem
If you need a logo for your new Github application you're welcome to use logo-small
{kind=link}
2. Find the installation ID
Once the Github application has been created, install it.
This will give you an opportunity to configure the permissions and scope of the Github application.
It is recommended that you give read-only permissions to any permissions that might include webhooks and read-write for code-suite and code-runs.
You might also utilize this Github App to perform other actions within Github with either other extensions or your own pipeline jobs. Remember to allow the correct permissions for all use cases.
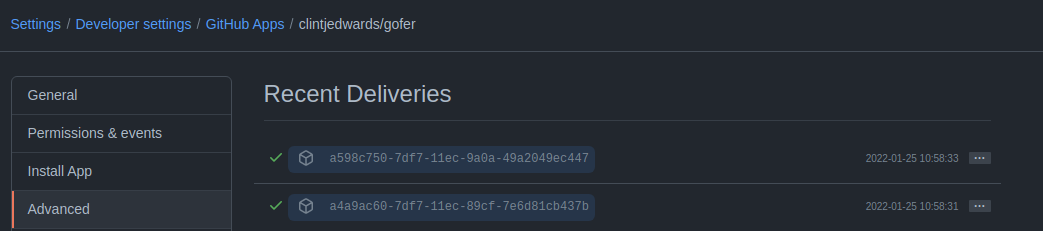
The installation ID is unfortunately hidden in an event that gets sent once the Github app has been created and installed. You can find it by navigating to the settings page for the Github application and then viewing it in the "Recent Deliveries" page.
🪧 These recent deliveries only last a short amount of time, so if you take a while to check on them, they might not exist anymore. If that has happened you should be able to create another event and that will create another recent delivery.
Events
Gofer's extensions have the ability to pass along event specific information in the form of environment variables that get injected into each container's run. Most of these variables are pulled from the webhook request that comes in.
Below is a breakdown of the environment variables that are passed to a run based on the event that was generated. You can find more information about the format the variables will be in by referencing the payloads for the event.
Events below are the only events that are supported.
| Event | Metadata |
|---|---|
| pull_request | "GOFER_EXTENSION_GITHUB_EVENT" "GOFER_EXTENSION_GITHUB_ACTION" "GOFER_EXTENSION_GITHUB_PULLREQUEST_HEAD_REF" "GOFER_EXTENSION_GITHUB_REPOSITORY" "GOFER_EXTENSION_GITHUB_PULLREQUEST_HEAD_SHA" "GOFER_EXTENSION_GITHUB_PULLREQUEST_AUTHOR_USERNAME" "GOFER_EXTENSION_GITHUB_PULLREQUEST_AUTHOR_EMAIL" "GOFER_EXTENSION_GITHUB_PULLREQUEST_AUTHOR_NAME" |
| pull_request_with_check | "GOFER_EXTENSION_GITHUB_EVENT" "GOFER_EXTENSION_GITHUB_ACTION" "GOFER_EXTENSION_GITHUB_PULLREQUEST_HEAD_REF" "GOFER_EXTENSION_GITHUB_REPOSITORY" "GOFER_EXTENSION_GITHUB_PULLREQUEST_HEAD_SHA" "GOFER_EXTENSION_GITHUB_PULLREQUEST_AUTHOR_USERNAME" "GOFER_EXTENSION_GITHUB_PULLREQUEST_AUTHOR_EMAIL" "GOFER_EXTENSION_GITHUB_PULLREQUEST_AUTHOR_NAME" |
| push | "GOFER_EXTENSION_GITHUB_EVENT": "GOFER_EXTENSION_GITHUB_ACTION" "GOFER_EXTENSION_GITHUB_REF" "GOFER_EXTENSION_GITHUB_REPOSITORY" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_ID" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_AUTHOR_NAME" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_AUTHOR_EMAIL" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_AUTHOR_USERNAME" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_COMMITTER_NAME" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_COMMITTER_EMAIL" "GOFER_EXTENSION_GITHUB_HEAD_COMMIT_COMMITTER_USERNAME" |
| release | "GOFER_EXTENSION_GITHUB_ACTION" "GOFER_EXTENSION_GITHUB_REPOSITORY" "GOFER_EXTENSION_GITHUB_RELEASE_TAG_NAME" "GOFER_EXTENSION_GITHUB_RELEASE_TARGET_COMMITISH" "GOFER_EXTENSION_GITHUB_RELEASE_AUTHOR_LOGIN" "GOFER_EXTENSION_GITHUB_RELEASE_CREATED_AT" "GOFER_EXTENSION_GITHUB_RELEASE_PUBLISHED_AT" |
The event pull_request_with_check is a special event not found within the Github API. It's primarily
to be used when the subscriber wants to report the job status back to the pull request based on the result of the job started
Command Line
Gofer's main way of providing interaction is through a command line application included in the Gofer binary.
This command line tool is how you upload pipelines, view runs, upload artifacts and many other common Gofer tasks.
To view the possible commands for the Gofer pipeline simply run gofer --help.
Configuration
The Gofer CLI accepts configuration through flags, environment variables, or a configuration file.
When multiple configuration sources are used the hierarchy is (from lowest to highest) config file values -> environment variables -> flags. Meaning that if you give the same configurations different values through a configuration file and through flags, the value given in the flag will prevail.
Flags
You can view Gofer's global flags by simply typing gofer -h.
Environment variables
You can also set configuration values through environment variables. Each environment variable has a prefix
of GOFER_.
For example, setting your API token:
export GOFER_TOKEN=mysupersecrettoken
gofer service token whoami
Each environment variable available is just the flag with a prefix of GOFER_.
export GOFER_HOST=localhost:8080
Configuration file
For convenience reasons Gofer can also use a standard configuration file. The language of this file is
TOML. Most of the options are simply in the form of key=value.
Configuration file locations
You can put your CLI configuration file in any of the following locations and Gofer will automatically detect and read from it(in order of first searched):
- The path given to the
--configflag - $HOME/.gofer.toml
- $HOME/.config/gofer.toml
Configuration file options
The options available in the configuration file are the same as the global flags:
gofer -h
...
Flags:
--detail
...
# The flag 'detail' maps back to the configuration file as the same name
# gofer.toml
detail = false
| configuration | type | description |
|---|---|---|
| namespace | string | The namespace ID of the namespace you'd like to default to. This is used to target specific namespaces when there might be multiple. |
| detail | string | Show extra detail for some commands (ex. Exact time instead of humanized) |
| output_format | string | Can be one of three values: plain, silent, json. Controls the output of CLI commands. |
| api_base_url | string | The URL of the Gofer server; used to point the CLI and that correct host. |
| token | string | The authentication token passed Gofer for Ident and Auth purposes. |
| debug | bool | Print debug statements. |
Example configuration file
# /home/clintjedwards/.gofer.toml
api_base_url = "http://127.0.0.1:8080/"
debug = false
detail = false
namespace = "default"
output_format = "plain"
token = "mysupersecrettoken"